PDF 라이브러리 vs 네이버 Clova OCR
제가 직접 작성한 것이 아닌 AutoRAG를 같이 만든 김병욱 연구원이 쓴 글입니다.
PDF 한글 추출 실험
지난 번 글에서는 PDF라이브러리 5종의 성능을 비교했다.
- PDF 라이브러리 중에서 가장 뛰어난 라이브러리가 궁금하다면?
=> PDF 라이브러리 5종 한글 추출 실험
실험에서 PDF 라이브러리도 예상보다 훨씬 뛰어난 성능을 보여주긴 했지만,
가끔씩 글자가 깨져버리기도 하고,
표는 전혀 추출해내지 못하는 모습이 살짝 아쉬웠다
그러다 문득 PDF 라이브러리와 전문 OCR의 성능은 얼마나 차이가 날 지 궁금해져 실험을 해보기로 했다.
그래서 이번 글에서는 PDF라이브러리 실험에서 공동 우승(?)을 했던 PDFMiner와, OCR중에서 네이버의 Clova OCR의 성능 비교를 간단히 해보도록 하겠다
결과 요약
- 네이버 OCR의 성능이 예상보다 훨씬 만족스러움
1. 텍스트
PDFMiner
-
5개의 파이썬 라이브러리 수준에서 사용할 수 있는 것 중 공동 1위 (지난 실험 결과)
-
⚠️ 20~30개 중 1개 꼴로 아예 텍스트가 깨져버리는 현상이 발생함 (실험 4번 참고)
네이버 Clova OCR
- 만족스러운 수준
2. 이미지
둘 다 불가능
3. 표
PDFMiner
- 텍스트만 그냥 추출되는 수준.
네이버 Clova OCR
- 놀라울 정도로 잘 함 (실험 3, 4, 5 참고)
실험 진행
-
네이버 OCR은 PDF 1 페이지 단위로만 지원해 PDF를 잘라서 실험
-
웹에서 네이버 Clova OCR 써보며 실험
실험 1: (제목, 목차, 내용이 모두 있는) 첫 페이지
📌원본 PDF

📌 추출 결과

성능은 비슷비슷했다.
확실히 OCR에서는 깨지는 글자가 거의 없는 것을 확인할 수 있긴 하다
실험 2: 텍스트만
📌원본 PDF

📌추출 결과

네이버 OCR 줄 바꿈까지 확실하게 해내는 모습이다.
실험 3: 표만 있는 경우
📌원본 PDF
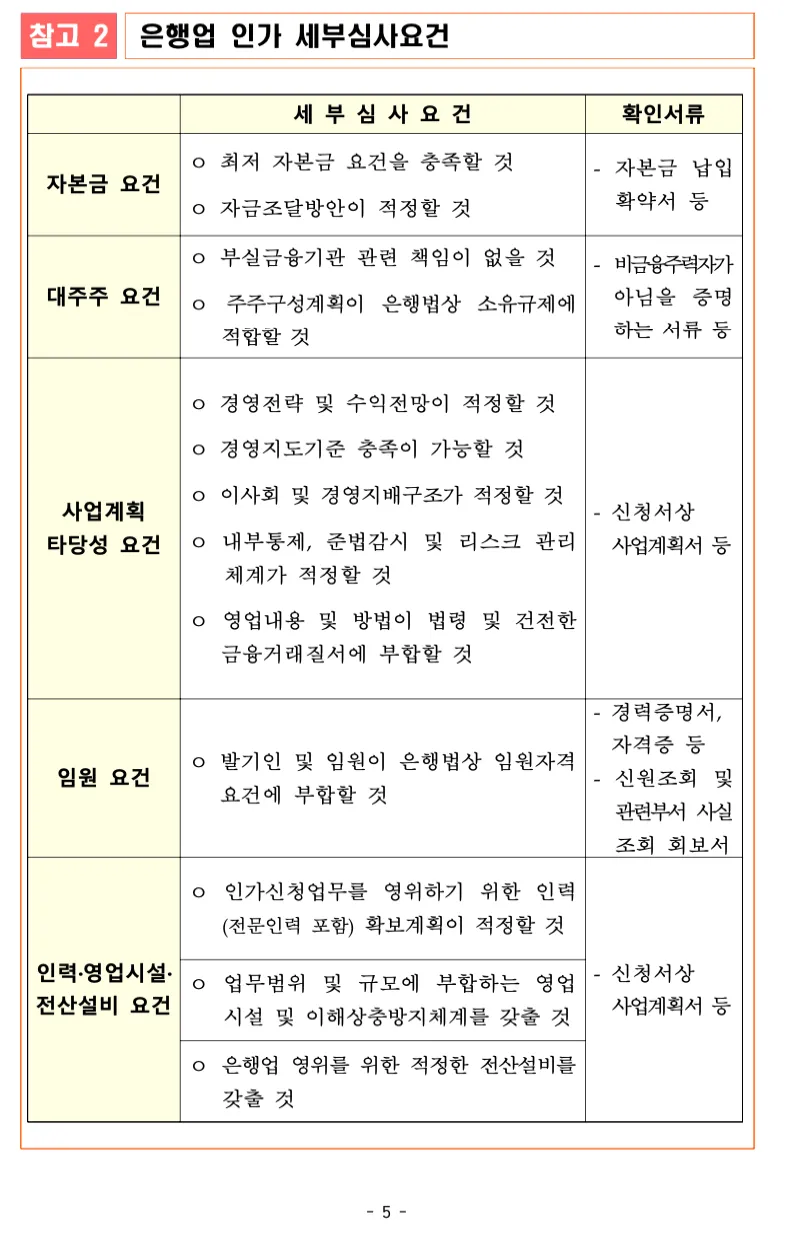
📌추출 결과
PDFMiner는 표는 불가능 하지만 OCR은 표를 잘 뽑아내는 모습이다. 역시 OCR은 표를 추출해내는 데에 강점이 있다.
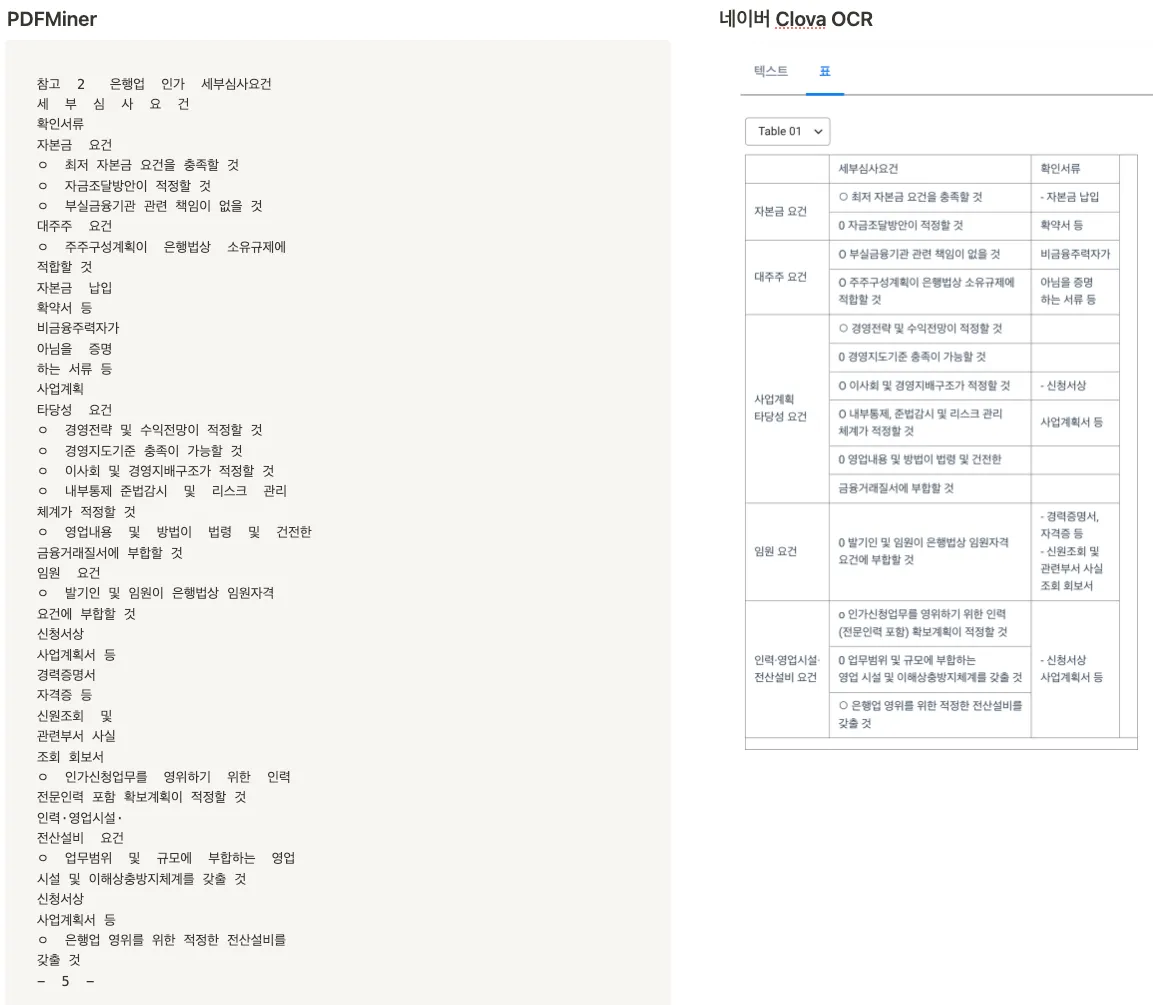
실험 4: 차트(이미지) + 표
📌원본 PDF

📌추출 결과

- 네이버의 표 추출 결과
-
PDFMiner는 잘 하다가도 갑자기 글자가 깨져버린다
-
차트(이미지)는 둘 다 불가능
-
표에 있어서는 확실히 네이버 Clova OCR이 강점이 있는 모습이다
번외 실험 5: 네이버의 복잡한 표 추출 성능 실험
문득 표를 잘 추출해내는 것을 보고, 복잡한 표도 잘 뽑아낼 수 있는 지가 궁금해졌다. 그래서 우리 팀에서도 꽤나 애를 먹었었던 이른바 표 속의 표, 어려운 표도 잘 뽑아낼 수 있는 지 확인해봤다.
📌원본 PDF
📌추출 결과

상당히 놀라운 결과이다.
개인적으로는 전혀 기대하고 있지 않았는데,, 표 속의 표까지 잘 뽑아낼 줄은 몰랐다.
더 읽어보기
-
AutoRAG 깃허브 => https://github.com/Marker-Inc-Korea/AutoRAG